Introduction
Last year, like many others before me, I discovered the
FOR UPDATE SKIP LOCKED
feature in postgres. It's a handy feature that allows you to solve a troublesome class of
problems elegantly by delegating all the work to the postgres machinery. This post documents
the end-to-end process that led me to it. I've also added a
button to make any assumptions, napkin math, etc
more accessible. Purely inspired by something I saw on Michael Nielsen's blog.

Problem Description
The high-level task was to build a feature to enable clients provision IP addresses for their virtual machines. This feature was going to be exposed by a public api. In terms of material constraints:
- The api service was running roughly 50 instances, globally distributed across a dozen regions. Client traffic was routed to the closest instance via anycast.
- The address supply was basically a couple of IP blocks, from which clients could make their pick. For simplicity, lets assume they were and .
- There were about 500,000 clients.
This is a reduced version of the problem, but representative enough of my dilemma at the time. [1]
Breakdown
To get a better sense of the problem, I did some napkin maths, starting with the address space.
- IPv4's 32-bit address space gives us 4.3 billion unique addresses.
- A single subnet provides 1024 addresses, so two of these blocks gives a total of 2048.
- Matching 2048 addresses to 500k clients results in a 1:244 address-to-client ratio. (this assumes perfect load balancing across addresses)
- There's going to be high contention if all clients requested IPs in parallel, since p(acquire) = 0.4%
=> 2048:500000 = 1:244 (we perform a division to get the ratio)
=> under equal distribution of load, each address has 244 possible suitors
=> which means each client request only has a 0.4% chance of claiming an address.
internet protocol version 4 (ipv4)
ipv4 address space
heuristics
2. This implies that 32bits can also be split into four groups of 8 bits: 232 = 28 × 28 × 28 × 28.
3. Each group of 8 bits is called an octet and an octet of memory can store numbers from 0 to 255.
4. This is why an ipv4 address is a sequence of 4 octets that look like this: [0-255].[0-255].[0-255].[0-255]
subnets
192.168.0.0 -> 11000000.10101000.00000000.00000000
192.168.0.1 -> 11000000.10101000.00000000.00000001
192.168.0.2 -> 11000000.10101000.00000000.00000010
192.168.0.3 -> 11000000.10101000.00000000.00000011
192.168.0.4 -> 11000000.10101000.00000000.00000100
192.168.0.5 -> 11000000.10101000.00000000.00000101
192.168.0.6 -> 11000000.10101000.00000000.00000110
192.168.0.7 -> 11000000.10101000.00000000.00000111
192.168.0.8 -> 11000000.10101000.00000000.00001000
192.168.0.9 -> 11000000.10101000.00000000.00001001
...
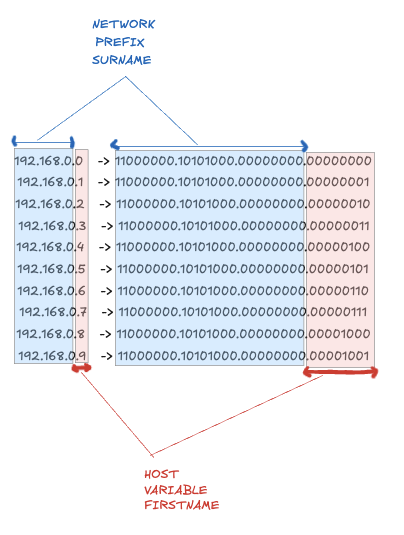
cidr notation (192.168.0.0/24)
192.168.0.0/24Now, an IP address is unique per single client. And so with 50 API instances capable of handling allocation requests concurrently, I needed to put in place a coordination mechanism to prevent multiple instances from assigning the same address to different clients. In the literature, this is the classic use-case for a (distributed) mutex.
However, a quick supply to demand analysis showed that roughly 497,952 clients will never be allocated an address, regardless of how long they retried or waited. And so allowing these clients to wait on a mutex was a wastage of compute. This meant I required not just any distributed mutex; it had to be non-blocking, so we could fail fast. breakdown
=> This means, if we have 500k clients and 2048 addresses, only 2048 clients can get an address.
=> The remaining (500,000 - 2048) 497,952 were doomed.
Honestly, this section was an exercise in worst case scenarios, but having no control over clients or the routing meant it was somewhat a reality.
Ideation
Implementing a non-blocking distributed mutex at the service level implied adding new infrastructure like Redis or DynamoDB [2]. In order to justify that operational overhead to management, I needed proof that I had exhausted all current options. Luckily for me, our api service was backed by postgres, so I began researching whether I could bend it to my needs.
I had a few (crude) ideas on my way to a good-enough solution, which I'm going to share in the spirit of transparency. Truth is, falsifying them led me to my final solution.
-
For each client request, randomly generate an
IP address in the subnet and try to claim it. We can rely on the "unique" index in postgres
to prevent duplicate allocations. It seems simple enough, but it's not great.
- It was prone to resource exhaustion. 500k clients guessing within a tiny 2048 space, coupled with an attempted db write which had an almost 0% chance of success.
- The lack of book-keeping(randomness), meant new client requests could guess an already allocated addresses, for which they were destined a rejection. Except, a rejection doesn't mean our address supply is depleted, so technically, they could retry, or the service could retry on their behalf. But the million dollar question becomes, at what point do they stop? When all 2048 addresses are claimed? When they finally grab one?
-
Create an IP-allocator class that sequentially
handles allocation requests using a buffer. This improves on the previous idea, but
introduces new problems I wasn't particularly interested in solving. (unless it was my last
resort)
- It required book-keeping between instances, for consistency.
- It required some book-keeping between storage and application.
- Lastly, a sequential queue meant higher latency. (sharding might help, see below)
-
Shard the subnets into 50 equal groups, and
assign each api instance instance a shard. Honestly, I loved this idea. It's elegant &
decentralized—doesn't require any distributed locking. Common knowledget at the org was
that, if you could solve a problem statically(without network+coordination), do it.
- The logical nature meant book-keeping.
- Due to the anycast routing, a dead instance OR an instance in a low traffic region can hog valuable IP addresses.
- Lastly I would have to figure out rebalancing, for example when we scale down instances.
A few of these ideas were workable, but I still had a hunch I could do better. Can you think about any other pros/cons for these ideas? Can you think of other solutions? I would love to hear them.
Breakthrough
Mid-research, I discovered the FOR UPDATE clause. But before I go into the details, I want you to assume we have this theoretical table called .
- This table represents
- A row from this table represents
- A column on the row indicates if an address is free or not.
- A column on the row indicates which client owns the address.
FOR UPDATE
The FOR UPDATE clause in postgres allows you to acquire a lock on all rows that match a given SELECT query. For a thought experiment, let's assume we have 2 clients, and , and they're both trying to claim a single address; .
In order for to claim in our address pool, it first needs to check if the address is free(select), and then claim it(update). However there's no atomic way to perform this 2-part operation in postgres, which means, there's a tiny gap between the select and update call where another client——could quickly steal the address.
This behaviour can easily be mitigated using FOR UPDATE. Invoking it gives exclusive access to . Any other client that attempts to claim the same row——will have to wait in-line till commits or rolls back.
For me, the biggest takeaway was from this clause was that, after is done with it's business, the postgres engine will of again, to ensure the is still free. This enforced some sort of serializability, which was a very good signal for consistency I was looking for.
FOR UPDATE NOWAIT
A good signal wasn't enough, because I was specifically looking for a non-blocking mutex. FOR UPDATE required all 243 clients to wait-inline and re-execute their queries on an address they had exactly 0% chance of getting [3]. This is how I found FOR UPDATE NOWAIT, which is a more interesting variant that doesn't wait for the locked row to be available. This looked like a good fit, I thought, since it would allow all 243 clients requests to fail immediately if they landed on the same address. But like I said in idea 1, failure to claim an address doesn't equate to an exhausted pool. With enough retries, the client could still get an address.
FOR UPDATE SKIP LOCKED
This magical clause gives you a non-blocking lock, but instead of early-exiting, it returns rows that are not locked. A perfect fit for my use case since it doesn't wait for any locks to be released, but also returns the next available row. This removes the need for a best-effort-retry. In prompt engineering terms, this is equivalent to telling the database, "hey psql, try your very best to find me an available IP. Don't make any mistakes".
Early on, I said the clause in postgres allows you to acquire a lock on that match a given SELECT query. The direct implication of this on the 2 variants might not be obvious so let's look at an example.
Lets assume have a pg table with 5 rows (a, b, c, d, e), where rows and are locked by another transaction.
SELECT *
FROM table
ORDER BY col ASC
→ Will return all rows (,
,
,
,
)
SELECT *
FROM table
ORDER BY col ASC
FOR UPDATE
→ Will return an error, because the first row it attempts to lock() is already locked.
SELECT *
FROM table
ORDER BY col ASC
FOR UPDATE
→ Will return rows ,
,
(skips the locked ones)
Hopefully it's clear now!
 "ok claude, make a billion dollar b2b todo app. make no mistakes."
"ok claude, make a billion dollar b2b todo app. make no mistakes."
Solution
I had a high-contention resource allocation problem, and my ideal solution was one that provided both distributed-consistency and rapid-rejection for failed allocations. Turns out, is all you need.
The conceptual model becomes clearer once you:
- remodel the problem as an exactly-once processing problem. [4]
- use postgres as a queue & invoke the clause to ensure exlusivity.
- think of the client as a consumer/worker.
With all the pieces in place, it was time to produce shareholder value. The first step was to generate all possible IPs in our subnets and seed our database with them, thereby creating a pool of available ip addresses. I'll provide some sample code to demonstrate the process.
CREATE TABLE client (
id bigint NOT NULL,
);
CREATE TABLE ip_address (
id bigint NOT NULL,
ip inet NOT NULL,
client_id bigint,
);
CREATE INDEX index_ip_address_on_client_id
ON ip_address USING btree (client_id);Then I added code to generate the IP supply and seed the database. In every subnet, you cant use the first & last address. You can figure out why for yourself.
func generate_all_ips_from_blocks(blocks []string) []string {
ips := []string{}
for _, b := range blocks {
range = IP.new(b).to_range()
// ignore first and last ip in block
range = [range[1], range[len(range)-1]]
for ip := range range {
ips = append(ips, ip)
}
}
return ips
}
blocks :=[]string{
“45.67.80.0/22”,
“203.0.112.0/22”,
}
unique_ips := generate_all_ips_from_blocks(blocks)
database.ip_address.insert_all(unique_ips) // the client_id is null, we are just creating a resource pool
Then for the actual allocation component, I created a database query to atomically assign available IPs to clients, in a non-blocking manner. A query error at this point meant either we've exhausted our supply or some other fancy programming problem happened. As a note, random helps spread the contention a bit, but it can be very expensive.
allocation_query = `
UPDATE ip_address
SET client_id = :client_id
WHERE id IN (
SELECT id
FROM ip_address
WHERE client_id IS NULL
ORDER BY random()
LIMIT 1
FOR UPDATE
SKIP LOCKED
)
RETURNING *
`
func allocate_ip_address(client_id: int) {
err := database.execute(allocation_query, {client_id})
if err != nil {
return client.send(“service out of ip addresses, try again later”)
}
}
api.handle(/allocate_ip_address, allocate_ip_address)
Once a client needed an IP, it just had to invoke a single call;
server.rpc.allocate_ip_address(client_id: 43943)Conclusion
I kept falsifying ideas based on the worse case scenario of 500k concurrent allocations. Deep down, I knew very well it wasn't practical. Especially because features like these always have an alpha & beta release to control traffic and get user feedback. In this case however, living by it was a very good-proxy which eventually guided me to an elegant solution.
Feel free to reach out if you have any questions or feedback.
IPV6
I added this section so I can mention a neat trick you could do for ipv6 allocations, since my original project included an IPv6 requirement. If you'd remember, I mentioned the human-friendly nature of the IPv4 address space as a good thing. Now, while that is true, the almost infiniteness of the IPv6 space made for easier allocation. By easier, I meant, static.
For IPv6, you can convert the client_id to hexadecimal and embed it directly in the address, enabling static assignments. Infact in our case, all we did was to convert the allocated IPv4 address to hex and embedded it in an IPv6 address.
[1] The IP subnets used in this post are probably not publicly routable. The real number of clients was several magnitudes higher, and lastly, the allocation was per client_vm, not client. And we most likely had more subnets iirc. (but these are all distractions) go back
[2] I didn't necessarily need these 2, but I wasn't implementing consensus algorithms if it wasn't required. Hence why the first option was to "buy", instead of build. go back
[3] The p(acquisition) = 0 assumes the transaction succeeded. If it fails or rollbacks, then someone else could stand a good chance of grabbing the address. go back
[4] Yes, the classic exactly-once problem is a bit inverted, but if you tone down the rationality a bit, you'll see the picture I'm trying to paint. go back